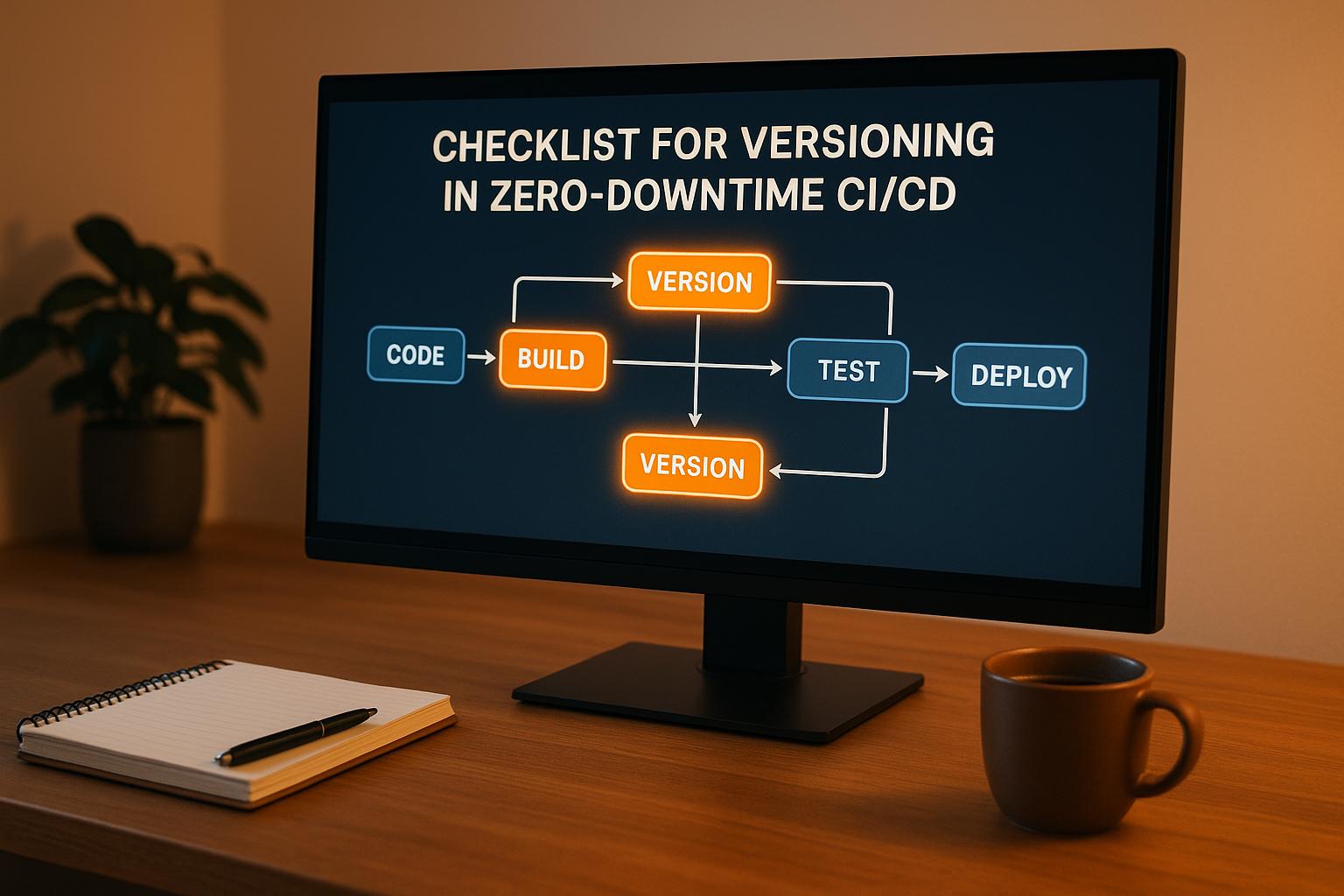
Zero-downtime deployments ensure that software updates happen without interrupting service. To make this possible, versioning plays a key role by enabling precise control over updates, rollbacks, and compatibility. Here's what you need to know:
- Semantic Versioning: Use the MAJOR.MINOR.PATCH format to clearly signal changes (e.g., breaking changes, new features, bug fixes).
- Immutable Artifacts: Build once, deploy everywhere. Never modify artifacts after they’re created to avoid inconsistencies.
- Feature Flags: Deploy new code without activating features immediately. This allows gradual rollouts and safer updates.
- Backward Compatibility: Ensure new updates don’t break existing systems by favouring additive changes and robust testing.
- Automation Tools: Use tools like Docker, Kubernetes, and Argo CD for consistent deployments, version tracking, and automated rollbacks.
- Monitoring and Rollbacks: Track performance metrics (e.g., error rates, response times) and automate rollbacks when thresholds are exceeded.
Why it matters: Downtime costs businesses an average of £11,000 per minute. By combining zero-downtime deployment practices with proper versioning, companies can reduce disruptions, lower costs, and improve reliability.
Key practices like semantic versioning, feature flags, and automation tools ensure smooth updates while keeping services online. These strategies are essential for industries like finance, e-commerce, and SaaS, where continuous availability is non-negotiable.
Azure DevOps CI/CD Pipeline for AKS Blue-Green Strategy
Core Versioning Practices for Zero-Downtime CI/CD
To achieve smooth, zero-downtime deployments, it's essential to adopt versioning practices that ensure releases are predictable, reliable, and easy to reverse. Below are key strategies to help maintain seamless deployment processes.
Use Semantic Versioning
Semantic Versioning, commonly referred to as SemVer, follows a structured format: MAJOR.MINOR.PATCH. Each part of this format conveys specific information about the release:
- MAJOR: Introduces breaking changes.
- MINOR: Adds new features that remain compatible with earlier versions.
- PATCH: Fixes bugs without altering functionality.
This standardised approach eliminates ambiguity, promotes consistency, and supports automation. Tools like semantic-release can integrate directly into CI/CD pipelines, automatically assigning version numbers based on commit messages and even generating release notes [5]. This not only reduces manual errors but also keeps the process consistent across all releases.
For Semantic Versioning to work effectively, clear documentation is critical. Teams need well-defined policies explaining when and why each version component should be updated. This shared understanding ensures consistency and simplifies rollback procedures, avoiding confusion during fast-paced deployments [4].
Keep Artifacts Unchanged After Build
A core principle of reliable deployments is ensuring that artifacts remain unaltered after the build process. Once a package is built, it should never be modified. This guarantees that the same artifact tested in staging is what gets deployed to production.
There is a key principle, that once a package has been built it should never need to be modified.- Michael Brunton-Spall
Immutable artifacts eliminate discrepancies that arise when environments differ. Modifiable artifacts often lead to the infamous it works on my machine
problem, causing unnecessary delays and frustrations.
To strengthen this practice, include as many dependencies as possible within the artifact itself. This reduces the risk of external dependency failures and ensures consistency across environments. Instead of pulling source code during deployment, rely solely on pre-built, tested artifacts.
Containerisation tools like Docker are particularly effective here. Once a Docker image is built and tagged, it remains unchanged, ensuring consistency across all deployments. This approach eliminates environment-specific issues that could disrupt services.
Use Feature Flags and Gradual Rollouts
Feature flags are game-changers for deployment strategies. They allow you to deploy code without immediately activating new features, separating deployment from feature release. This means you can introduce substantial changes without risking downtime.
Feature flags also enable gradual rollouts, where updates are released incrementally to specific user groups. For instance, you might first activate a feature for internal teams before slowly expanding it to a wider audience [6]. This avoids the risks associated with big-bang
deployments that affect all users at once.
Dynamic API versioning is another advanced use of feature flags. By allowing multiple API versions to coexist, feature flags can control which version a client uses. This ensures legacy clients can continue operating while newer clients adopt updated features [6].
However, feature flags require careful management. Establish robust governance processes, including approvals and role-based access controls, to prevent unauthorised changes [6]. Each flag should have a defined lifecycle, and its removal should be part of the definition of done
to avoid accumulating unnecessary technical debt.
Maintain Backward Compatibility
Maintaining backward compatibility is critical for ensuring uninterrupted service during updates. This can often be achieved by favouring additive changes - such as introducing new fields rather than altering existing ones - and by using multi-stage deployments for any unavoidable breaking changes.
In microservices architectures, compatibility is especially important. Service interfaces, message formats, and event schemas must evolve without disrupting existing consumers. Techniques like versioned message formats and graceful degradation help maintain availability during updates.
Automated testing plays a vital role in verifying compatibility. Integration tests, contract tests, and backward compatibility test suites can identify potential issues before they escalate into production problems. These tests ensure that newer versions work seamlessly with existing clients and data.
Backward compatibility also simplifies rollbacks. If a new deployment introduces issues, you can confidently revert to a previous version, knowing it will continue to work without disruption. This capability is essential for frequent deployments while aiming for zero downtime.
Automation Tools for Versioning in CI/CD
Automation tools simplify the management of artifacts, deployments, and monitoring, enabling seamless operations in zero-downtime CI/CD workflows. These tools ensure consistency and traceability of versions throughout the pipeline.
Add Artifact Repositories to Pipelines
Artifact repositories serve as central hubs for storing compiled binaries, libraries, deployment packages, container images, documentation, and configuration files [9]. By centralising these resources, teams can improve accessibility, enhance security, and minimise redundancy [15].
Effective artifact versioning is a cornerstone of a reliable and efficient DevOps process.– Gurukul DevOps [14]
Popular platforms like JFrog Artifactory, Sonatype Nexus, and AWS CodeArtifact offer robust versioning features. These tools automatically track artifact versions, maintain metadata, and integrate seamlessly with existing build systems. When choosing a repository, ensure it aligns with your versioning strategy and integrates directly with your CI/CD pipeline for smooth operations [14][15].
For GitLab users, a common challenge is the lack of native support for passing artifacts between pipelines. A practical solution is to upload artifacts to GitLab's built-in package repository - or an external one - and download them in subsequent pipelines. Implementing cleanup rules is crucial to avoid storage issues [8].
Automation scripts can handle artifact uploads, downloads, and management, reducing the risk of human error and ensuring consistency across environments [7]. Additionally, workflows that automatically tag versions in your version control system create a clear link between code changes and deployable packages [14].
How you manage artifacts directly impacts the efficiency of your software pipelines and the decisions that follow [15]. Deployment orchestration tools take this further by automating and securing the release process.
Use Deployment Orchestration Tools
Deployment orchestration tools automate the end-to-end process of application deployment, especially in Kubernetes environments. They enable advanced deployment methods like blue–green deployments, canary releases, and rolling updates, ensuring zero downtime [10][11][13].
Kubernetes supports rolling updates natively, allowing pods to be updated incrementally, ensuring new versions deploy without interrupting services. Deployment descriptors manage these updates to limit downtime [11].
For blue–green deployments in Kubernetes, services and labels direct traffic between versions. The new (green) version is deployed alongside the existing (blue) version, but traffic isn’t routed to it until testing confirms its stability. Once verified, the service selector is updated to redirect traffic to the green version [11].
Argo CD uses a declarative GitOps approach, synchronising the desired state in Git with the live Kubernetes cluster. It enables automated rollouts with built-in version control, rollback options, and approval gates for safer deployments [13].
| Deployment Strategy | Traffic Management | Rollback Method |
|---|---|---|
| Blue/Green | Immediate traffic switch | Revert to the blue environment |
| Canary | Gradual traffic increase | Stop or scale back deployment |
| Rolling | Sequential updates | Revert updates batch by batch |
Tools like Terraform complement orchestration by managing infrastructure environments consistently, including blue–green setups [10]. Load balancers and reverse proxies, managed through orchestration tools, efficiently direct traffic between environments during deployments [10][12]. Monitoring and rollback systems further enhance deployment safety.
Set Up Monitoring and Rollback Systems
Real-time monitoring and automated rollback mechanisms are essential for minimising deployment risks. Downtime can cost businesses as much as £7,200 per minute [12], making these systems critical.
Implement liveness and readiness probes in Kubernetes to continuously monitor pod health. These probes can trigger rollbacks before users experience any disruption [11]. Additionally, feature flags allow teams to deploy new features in an inactive state, enabling controlled activation without requiring a full redeployment. This approach separates deployment from feature activation, offering precise control over the user experience [11].
Automated rollback systems can quickly revert to previous versions if new deployments fail health checks or performance benchmarks [11][12]. Load balancers and reverse proxies ensure traffic is routed only to healthy instances, keeping services available even during deployment [10][12].
ZDD is becoming not just a desirable option, but a necessary requirement in today's software development landscape. I believe that particular attention should be paid to testing and rollback mechanisms - an automated rollback can save a company's reputation and finances.– Dmitry Plikus, DevOps Engineer at SoftTeco [12]
Monitoring systems should track critical metrics like response times, error rates, resource usage, and user experience. When these metrics exceed thresholds, automated rollbacks can prevent small issues from escalating into major outages, protecting both revenue and reputation.
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Versioning Checklist for Zero-Downtime CI/CD
This checklist brings together versioning practices and automation strategies to ensure smooth and uninterrupted CI/CD processes.
Set and Enforce Versioning Standards
Use Semantic Versioning (MAJOR.MINOR.PATCH) to clearly communicate the type of changes in each release [1]. Align your CI/CD pipeline’s goals with your organisation's broader strategy [16]. Establish clear and consistent naming conventions for releases to differentiate between stages effectively [1]. Document these standards in an easily accessible format, ensuring all team members understand how version increments impact the workflow.
Automate version tagging in your version control system to create a direct link between code changes and deployable packages. This not only streamlines tracking but also simplifies rollbacks when needed. These foundational standards support the automated workflows detailed below.
Automate Artifact Management
Treat build artifacts as the definitive product of your source code. Store them in a central repository, such as Nexus, to maintain organisation and accessibility [17]. Automate version updates for artifacts using semantic versioning [18], eliminating the need for manual intervention. Your CI server should ensure that the same build artifact is used consistently across all test environments [17], guaranteeing that what is tested matches what is deployed to production.
Set up retention policies and automate cleanup tasks [18] to prevent storage issues while keeping essential historical versions. Validate artifacts with checksums or digital signatures to ensure their integrity and authenticity.
Test Service and Version Compatibility
Before deployment, run a comprehensive suite of tests, including unit, integration, performance, and canary tests, to confirm service compatibility. Following the testing pyramid principle, prioritise fast and cost-effective unit tests, supported by fewer but more detailed integration and system-level tests.
Leverage ephemeral environments, containers, or sandboxed namespaces for testing. This isolation ensures that compatibility tests simulate real-world conditions. Canary testing in production adds an extra layer of validation by deploying new code to a small subset of servers first. This approach helps catch issues that might not appear in staging environments, reducing the risk of widespread user impact.
Document and Automate Rollback Steps
Automate rollback procedures to quickly revert to stable versions when issues arise [19]. Define clear triggers, assign responsibilities, and establish communication protocols for rollback scenarios. Rollback plans should include database schema changes, configuration updates, and service dependencies.
Feature toggles offer an additional safeguard, enabling teams to activate or deactivate features in production without redeploying code [16]. Regularly test rollback processes through planned exercises to ensure they function effectively under pressure. These tests also highlight areas where rollback speed and reliability can be improved.
Use automated checks to monitor rollback success. These checks confirm system stability and ensure that all dependent services remain operational after a rollback.
Monitor Deployments and User Impact
Keep a close eye on response times, error rates, and resource usage [2] to identify issues before they escalate. Set up automated alerts and rollbacks for when performance thresholds are exceeded.
Implement a monitoring strategy that covers technical metrics, business outcomes, and user experience. Technical monitoring focuses on system performance and resource usage, while business monitoring tracks metrics like conversion rates, transaction volumes, and feature usage. User experience monitoring examines factors such as page load times, feature adoption, and support tickets.
Correlate deployment events with monitoring data to determine whether issues are linked to recent changes. This information helps decide whether to move forward with a deployment or initiate a rollback. Additionally, gather user feedback and satisfaction scores during deployments to ensure changes meet expectations.
| Monitoring Category | Key Metrics | Response Actions |
|---|---|---|
| Technical Performance | Response time, error rates, CPU/memory usage | Scale resources, optimise code, rollback if critical |
| Business Impact | Conversion rates, transaction volume, revenue | Pause rollout, investigate user experience issues |
| User Experience | Page load times, feature adoption, support tickets | Adjust feature toggles, improve documentation, gather feedback |
Cost Benefits of Versioning and Zero-Downtime Deployment
Pairing effective versioning with zero-downtime deployments doesn’t just prevent outages - it also boosts operational efficiency and trims cloud expenses.
Reduce Downtime Costs
The financial sting of service interruptions is no small matter. On average, unplanned downtime costs businesses around £11,000 per minute, and for large enterprises, this figure can climb to £19,000 [22]. Beyond the immediate revenue loss, downtime can lead to customer dissatisfaction, churn, and long-term reputational damage.
By implementing solid versioning practices, organisations can respond to issues more rapidly, significantly mitigating these risks. For example, businesses using CI/CD pipelines report a 33% faster time-to-market and a 50% lower change failure rate compared to traditional methods [21].
Take Amazon, for instance. They use immutable deployments to push thousands of updates to production daily [20]. Similarly, Netflix employs Spinnaker with infrastructure templates, enabling them to manage complex cloud deployments and scale quickly without sacrificing service availability [20]. These approaches not only minimise downtime but also free up teams to focus on developing revenue-generating features instead of putting out fires.
Improve Cloud Resource Usage
Zero-downtime deployments also optimise how cloud resources are utilised, leading to reduced costs. Traditional deployment methods often require duplicate environments during updates, doubling resource usage. In contrast, modern strategies like blue-green deployments and rolling updates eliminate this inefficiency.
Companies that adopt CI/CD practices typically see a 50% reduction in development and operations costs [21]. Automation plays a big role here, cutting down on manual effort and reducing human error. Moreover, cloud providers’ features - such as auto-scaling, rightsizing recommendations, and pay-as-you-go pricing - work best when deployments are predictable and efficient.
Saving on infrastructure isn't just about trimming budgets – it's about realigning your tech to drive more value with less waste... When you reduce unnecessary overhead, you're not just cutting costs – you're creating space to innovate, scale, and outperform competitors. That's the power of smart infrastructure decisions.– Oleksandr Prokopiev, CEO, Artjoker [23]
According to IDC, businesses often overspend on cloud resources by 20–30% [25]. Effective versioning provides historical data on resource usage during deployments, helping teams plan capacity more accurately. This might involve rightsizing instances, scheduling non-critical workloads during quieter periods, or removing idle resources. Adopting multi-cloud strategies with consistent versioning can also reduce costs by allowing flexibility in vendor selection and benefiting from competitive regional pricing.
Custom Solutions for Hybrid and Private Clouds
In hybrid and private cloud environments, tailored versioning strategies can unlock even greater cost savings. Kearney estimates that organisations using hybrid cloud portfolios can reduce their total cost of ownership by 15–18% within 18 months, and by more than 25% over 2–3 years. These setups also enable faster recovery from major incidents (up to 70% faster) and fewer change failures (60% fewer) [24].
Capital One is a prime example. By implementing AI-driven workload placement across its hybrid cloud infrastructure, the company slashed its infrastructure costs by 40% [26]. This shows how intelligent versioning and deployment strategies can optimise workload distribution based on factors like cost, performance, and compliance.
Hybrid clouds offer the flexibility to place workloads where they make the most sense. Sensitive data can be kept in private environments for security, while public clouds handle variable workloads. This balance, however, depends on sophisticated versioning to ensure consistency across different platforms.
Private clouds, on the other hand, are particularly beneficial for organisations with steady capacity requirements. Unlike public clouds, which operate on an OpEx cost model, private clouds involve CapEx [25]. For businesses with high monthly cloud spending, efficient versioning can maximise private infrastructure usage, making it a more cost-effective option over time.
A smart hybrid strategy should focus on allocating about 80% of cloud spend to a primary provider, keeping the remaining 20% for secondary providers to maintain flexibility and avoid vendor lock-in [24]. Unified versioning across environments ensures seamless workload migration, enabling organisations to capitalise on cost-saving opportunities as they arise.
Hokstad Consulting offers expertise in cutting cloud infrastructure costs through strategic versioning and deployment practices. Their services claim to reduce expenses by 30–50% while implementing zero-downtime deployment strategies tailored to hybrid and private cloud setups. With their No Savings, No Fee
model, businesses only pay when measurable cost reductions are achieved.
Key Points for Versioning in Zero-Downtime CI/CD
Achieving smooth versioning in zero-downtime CI/CD pipelines hinges on a mix of clear standards, automation, and smart cost management. Semantic versioning is particularly useful for conveying the nature of changes. For instance, in a Kubernetes deployment, you might see a container image versioned as 1.5.5, the deployment as 1.5.8, and the overall application as 1.6.9 [1].
Ensuring backward compatibility is another critical piece of the puzzle. It helps avoid disruptions during updates. Take Stripe, for example - they maintain fixed API versions, allowing customers to upgrade at their own pace without breaking existing integrations [30].
Automation is a game-changer in CI/CD workflows. Leading teams deploy code 208 times more frequently and achieve lead times that are 106 times faster [29]. Automating tasks like builds, tests, deployments, rollbacks, and monitoring reduces manual errors, saves time, and makes the entire process more efficient [28]. Even release naming and management benefit from automation.
Speaking of releases, how they’re labelled matters. Semantic versioning is a good starting point, but adding labels like stable, canary, or alpha provides extra clarity about software readiness. For example, tagging a deployment as release-stage: canary helps teams quickly understand its role in the release process and decide if a rollback is necessary [1].
Strategies such as blue-green and canary deployments, when combined with feature flags, lower the risks of updates while ensuring uninterrupted service [29][30][3].
The financial upside of efficient versioning isn’t just about preventing downtime. Faster, more dependable deployments free up developers to focus on innovation, while quick bug fixes minimise costly interruptions [27].
Balancing theoretical understanding with practical examples is vital in mastering versioning, releases, and rollouts in a CI/CD environment. Implementing these best practices streamlines the deployment process and ensures greater reliability and maintainability of software applications.
When paired with robust monitoring and automated rollback mechanisms, these practices form a solid foundation for zero-downtime deployments [1].
FAQs
How does semantic versioning support zero-downtime deployments?
Semantic versioning is an essential tool for achieving reliable zero-downtime deployments. By clearly outlining the type of changes in software updates, it helps teams understand whether updates are backward-compatible, add new features, or involve breaking changes.
This clarity allows for more effective deployment strategies, such as blue-green deployments or canary releases, which minimise the risk of service disruptions. It also ensures that different components remain compatible, making updates more predictable and keeping services running smoothly during rollouts.
How do feature flags help reduce risks during software updates, and what are the best practices for using them effectively?
Feature flags play a key role in reducing risks during software updates. They let developers switch specific features on or off without deploying new code, making it easier to test changes step by step and quickly address any problems that come up. This method ensures updates roll out more smoothly and minimises the chance of downtime.
To make the most of feature flags, consider these practical tips:
- Choose clear and consistent names for your flags to keep them well-organised and easy to understand.
- Centralise their management to streamline control across your systems and avoid confusion.
- Remove outdated flags regularly to prevent unnecessary complexity in your codebase.
- Set a defined lifespan for flags, so they serve their purpose without becoming permanent fixtures.
When applied thoughtfully, feature flags allow for safer, more controlled deployments, helping businesses stay stable while continuing to evolve.
Why is backward compatibility important for zero-downtime CI/CD, and how can it be achieved?
Backward compatibility plays a key role in achieving zero-downtime CI/CD. It ensures that new updates integrate smoothly with existing versions, avoiding disruptions during deployment and keeping services running seamlessly for users.
To make this happen, you can adopt strategies like blue-green deployments, which let you switch between software versions safely, and feature flags, which allow you to roll out new features gradually while still supporting older functionality. It's also important to design database changes with backward compatibility in mind and thoroughly test APIs and data transitions. These approaches help minimise downtime risks and maintain a stable deployment process.