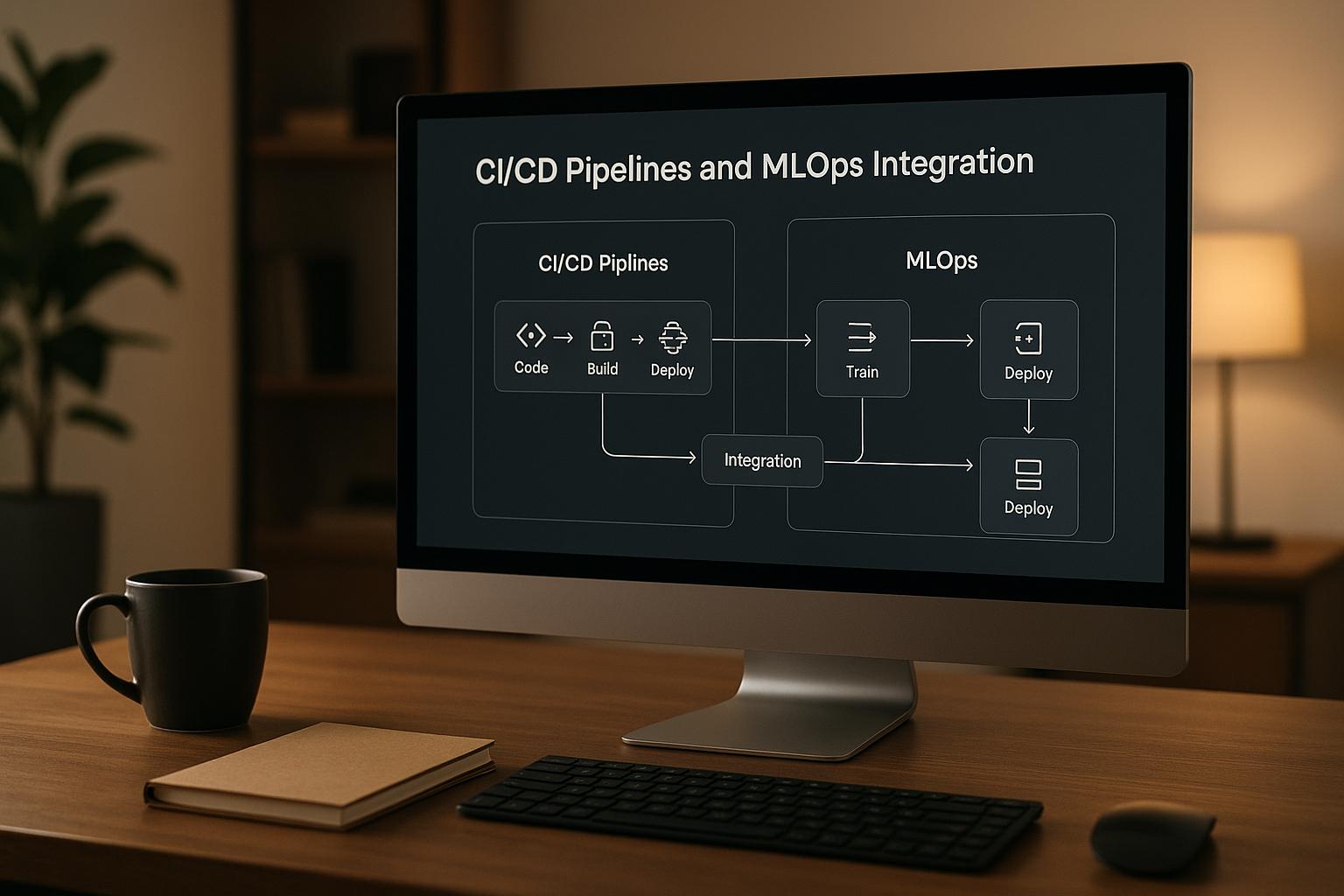
Machine learning systems need more than just code updates - they rely on data, models, and infrastructure that evolve constantly. Standard CI/CD pipelines, designed for software, fall short when managing these complexities. That’s where MLOps comes in, bridging the gap between ML workflows and deployment pipelines.
Key Takeaways:
- What’s Different About ML? Unlike software, ML systems depend on dynamic data, model versioning, and performance monitoring.
- Why MLOps? It automates training, testing, deployment, and monitoring while ensuring traceability and reducing errors.
- The Benefits: Faster deployment, fewer errors, and better model tracking. It also helps manage costs and ensures compliance.
- How It Works: MLOps pipelines include data validation, automated training, model testing, deployment strategies (e.g., A/B testing), and monitoring.
- Tools to Use: Options like Kubeflow, MLflow, Jenkins, and Apache Airflow handle the unique needs of ML workflows.
- Best Practices: Use modular pipelines, automate testing, and track everything - code, data, and models.
MLOps-integrated CI/CD pipelines make deploying ML models smoother and more reliable, helping organisations keep up with the demands of machine learning.
Bringing CI/CD Practices to Machine Learning with MLOps - Robert Hafner, Comcast

Core Components of MLOps-Enhanced CI/CD Pipelines
Building effective MLOps-enhanced CI/CD pipelines requires a well-thought-out framework capable of managing data, models, and code seamlessly. Unlike traditional CI/CD pipelines, which focus primarily on code changes, these pipelines must coordinate intricate workflows that involve datasets, machine learning models, infrastructure, and application code. They operate across multiple environments and rely on specialised tools tailored to the unique challenges of machine learning workflows. Let’s break down the key components and stages of these pipelines.
Stages of an MLOps-Integrated Pipeline
MLOps-enhanced CI/CD pipelines expand upon traditional stages by incorporating machine learning-specific processes to ensure models are effectively trained, validated, and deployed. Here’s how the process unfolds:
Data Validation: This is one of the earliest and most critical steps. It ensures that data meets quality standards and complies with schema requirements before it’s used for model training.
Automated Model Training: At this stage, the pipeline provisions the necessary compute resources, runs training jobs, and records metrics. Tasks like hyperparameter tuning and cross-validation are automated to optimise model performance. Workloads are containerised for scalability and reproducibility.
Model Testing: Beyond standard software testing, this stage evaluates the model’s accuracy, bias, fairness, and overall performance across various data segments. Integration tests ensure the model functions properly within existing systems and APIs.
Model Deployment: This stage manages the infrastructure for serving models. It supports strategies like blue-green deployments, canary releases, and A/B testing. Automated rollback mechanisms are in place to revert to previous versions if performance issues arise.
Monitoring: Once deployed, models are monitored for issues like concept drift, data quality problems, or performance degradation. If significant changes are detected, the system can trigger retraining pipelines or alert the operations team.
Throughout these stages, accurate versioning of code, data, and models ensures traceability and smooth workflows.
Versioning Data, Models, and Code
Effective versioning is vital for MLOps pipelines, as it tracks three interconnected elements: code, data, and trained models.
Code Versioning: Managed through tools like Git, this tracks changes in application and model code.
Data Versioning: Tools like DVC (Data Version Control) integrate with Git to handle large datasets, creating immutable snapshots of training data and preprocessing pipelines. This approach links specific data versions to corresponding code changes.
Model Versioning: This goes beyond storing the trained model. It includes metadata such as hyperparameters, training metrics, and the associated code and data versions. Model registries serve as centralised repositories, making it easier to compare different iterations and track performance improvements.
Versioning systems also track dependencies between components. For instance, when a new dataset version is introduced, the system can identify which models need retraining and trigger the necessary workflows. Similarly, changes in feature engineering code propagate to retraining pipelines automatically. Semantic versioning is often used for models, with major versions indicating significant architecture changes and minor versions reflecting updates like retraining or parameter adjustments.
Pipeline Orchestration Tools for MLOps
To manage the complexity of MLOps workflows, orchestration tools play a crucial role. These platforms coordinate tasks across systems, addressing both CI/CD and machine learning-specific needs.
Kubeflow: Built on Kubernetes, Kubeflow supports the full machine learning lifecycle. It includes tools for notebook servers, training jobs, hyperparameter tuning, and model serving. Its integration with Kubernetes allows for scalable workflows and efficient resource management.
MLflow: This tool focuses on experiment tracking and model lifecycle management. It provides APIs for logging metrics, parameters, and artifacts. Its model registry integrates seamlessly with CI/CD pipelines, enabling automated promotion of models based on performance criteria. MLflow is ideal for teams looking to enhance existing CI/CD systems without overhauling them.
Jenkins: A well-known CI/CD tool, Jenkins can be adapted for MLOps workflows through plugins and integrations. It’s particularly valuable for organisations with existing Jenkins infrastructure, though it requires additional configuration to meet machine learning-specific demands.
Apache Airflow: Known for its ability to handle complex workflows, Airflow uses a directed acyclic graph (DAG) approach to manage tasks. It’s effective for coordinating data pipelines, training jobs, and deployment processes, offering excellent visibility and error-handling capabilities.
The choice of orchestration tool often depends on the organisation’s current infrastructure and expertise. For example, teams with strong Kubernetes experience might favour Kubeflow, while those with established CI/CD systems may lean towards MLflow or Jenkins. The ultimate goal is to select a platform that can handle the intricacies of machine learning workflows while integrating with existing processes efficiently.
Designing Continuous Workflows for Machine Learning Models
Developing continuous workflows for machine learning (ML) models requires a tailored approach to ensure they address data dependencies, performance variations, and the iterative nature of experimentation. These workflows must support both scheduled retraining and event-driven updates, all while maintaining model quality.
Automated triggers play a key role in these workflows, responding to changes in data, model performance, or business requirements. The challenge lies in balancing model freshness, resource usage, and stability. Unlike traditional CI/CD workflows that focus on code changes, ML workflows need to monitor multiple signals simultaneously, making intelligent decisions about retraining, testing, and deployment. Let’s explore how to implement these workflows effectively.
Building Continuous Training Pipelines
Continuous training pipelines are at the heart of MLOps, ensuring models stay up to date as new data becomes available or performance declines. These pipelines must accommodate different data volumes, computational needs, and training frequencies based on the model and business priorities.
- Data-driven triggers: These monitor incoming data streams and initiate retraining when significant new data accumulates or when data distribution shifts. For instance, a recommendation system might retrain daily, while a fraud detection model may require more frequent updates.
- Performance-based triggers: These track metrics like accuracy, precision, and recall. If performance dips below a set threshold, retraining is triggered. This is particularly useful in dynamic environments where gradual concept drift occurs.
- Scheduled retraining: By updating models at regular intervals, this approach ensures fresh training data, even if performance metrics remain stable. Many organisations combine this with event-driven triggers to balance computational costs and model updates.
Efficient resource management is vital. Pipelines should scale computational resources up during training and down during idle periods. Tools like Kubernetes can allocate GPU-enabled nodes for training and release them once the task is complete.
Incremental learning offers another advantage by updating models with new data rather than retraining from scratch. This method saves time and resources, making it ideal for large-scale deployments.
Automated Testing for Model Quality
Continuous retraining demands rigorous testing to ensure models meet quality standards before deployment. Model testing in this context goes beyond traditional unit tests, incorporating statistical validation, bias detection, and integration testing.
- Statistical tests: These verify that new models meet performance thresholds across various data segments and use cases. By comparing new versions to baseline metrics, teams can confirm improvements and avoid regressions. Cross-validation helps assess how well models generalise to different data distributions.
- Bias and fairness testing: As ML models are increasingly used in sensitive applications, it’s critical to evaluate predictions across demographic groups, regions, or other segments to detect potential biases. These tests must align with specific use cases and regulatory standards.
- Integration testing: Updated models must integrate smoothly with existing systems and APIs. This involves verifying input/output schemas, response times, and compatibility with downstream applications.
For deployment, A/B testing frameworks are invaluable. They route a portion of real production traffic to the new model, monitoring key metrics. If the new model performs better, traffic is gradually shifted; otherwise, the system reverts to the previous version. Similarly, shadow testing runs new models alongside production ones, using real data without affecting user-facing results. This provides another layer of validation while minimising risks.
Experiment Tracking and Model Registry Integration
To ensure transparency and smooth operations, experiment tracking and model registry systems must work seamlessly together. These tools capture detailed metadata about training runs, model versions, and deployment histories, providing data scientists and operations teams with easy access to critical information.
- Experiment tracking systems: These log training parameters, metrics, and artefacts for every model run. This allows teams to compare approaches, replicate results, and identify successful strategies. By integrating with CI/CD pipelines, this process can be automated, reducing manual effort.
- Model registries: Acting as central repositories, these store not only the model artefacts but also metadata, performance metrics, and lineage details. Features like model versioning, approval workflows, and promotion criteria streamline the management of models.
Lineage tracking connects models to their training data, code, and infrastructure configurations. This is crucial for debugging, understanding performance changes, and meeting compliance requirements. If issues arise in production, lineage data helps pinpoint the root cause quickly.
Approval workflows add a layer of oversight, with some models requiring manual review before deployment. Others can be promoted automatically if they meet predefined performance criteria.
Finally, metadata management tracks training and resource metrics, supporting cost management by identifying resource-heavy processes. This helps teams make informed decisions about deployment strategies.
Need help optimizing your cloud costs?
Get expert advice on how to reduce your cloud expenses without sacrificing performance.
Best Practices for Scaling and Optimising MLOps Pipelines
As machine learning operations become more ingrained in enterprise settings, organisations need pipelines that are scalable, efficient, and compliant. Unlike traditional software, ML pipelines deal with massive datasets, resource-heavy training processes, and strict regulatory demands - all while ensuring smooth operations. These practices align with integrating MLOps into CI/CD frameworks, focusing on systems that grow alongside organisational needs without sacrificing performance or security.
Scaling successfully requires a shift in mindset. Instead of treating ML workflows as standalone processes, enterprises must design systems that adapt to changing needs, manage varying workloads, and deliver consistent performance across environments. This ensures pipelines function efficiently, whether dealing with gigabytes or terabytes of data.
Modular and Extensible Pipeline Design
A modular approach is the backbone of scalable MLOps. Each pipeline component - from data ingestion to deployment - should operate independently while maintaining clear connections with other stages. This setup allows teams to update or replace components without disrupting the entire system, reducing risks and speeding up iterations.
Breaking down workflows into isolated components lets teams separately manage tasks like data preprocessing, feature engineering, model training, and deployment. Using containerisation tools like Docker ensures consistent performance across environments, eliminating compatibility issues.
API-driven interfaces between components make integration and updates straightforward. For instance, a new feature engineering algorithm can be introduced as a service without affecting downstream processes, as long as the API contract remains intact.
Version control should go beyond code to include configurations, infrastructure details, and deployment manifests. Tools like GitOps help manage pipeline definitions as code, providing audit trails and rollback options. This ensures that changes to pipelines are reviewed with the same rigour as application code, maintaining quality even as teams scale.
Once a modular structure is in place, the focus shifts to managing costs effectively.
Cost Optimisation in Machine Learning Pipelines
Machine learning workloads can become expensive, especially with large models and extensive datasets. Efficient resource management is key to keeping costs under control, ensuring resources are scaled up when needed and scaled down during idle times.
Leverage spot instances or preemptible computing for cost-effective operations, paired with proper checkpointing to avoid data loss. Auto-scaling policies should monitor CPU, memory, and workload demands, dynamically allocating GPU resources during peak times and scaling back during lulls to prevent waste.
Optimising data pipelines is another way to cut costs. Implement lifecycle policies to move older datasets to cheaper storage tiers and use compression techniques to reduce storage needs without compromising quality. Caching plays a critical role here by storing intermediate results, avoiding redundant computations when multiple models share similar feature sets. Incremental processing, which updates only the changed data, also helps reduce computational overhead.
While cost-saving measures are essential, they must be paired with robust security to protect data and ensure compliance.
Security and Governance in MLOps
Security in MLOps goes beyond standard application protection. It involves safeguarding data privacy, maintaining model integrity, and meeting regulatory requirements. With ML models often handling sensitive information, strong security measures are a must.
Data encryption is essential at every stage - whether data is stored, in transit, or actively processed. This includes training datasets, model artefacts, and any intermediate data. Although cloud platforms often offer built-in encryption, organisations must ensure encryption keys are managed and rotated according to security policies.
Adopt least privilege access controls to limit access to essential resources. For example, data scientists might only have read access to training datasets, while operations teams handle deployments without needing direct access to sensitive information. Role-Based Access Control (RBAC) can automate these permissions, enhancing security while simplifying management.
Tracking model lineage, performance, and approvals is critical, especially in regulated industries. Organisations must often prove that models meet specific criteria before deployment. Detailed audit trails documenting changes and approvals support compliance and accountability.
Finally, vulnerability scanning should address ML-specific risks like model poisoning, adversarial attacks, and data leakage. Regular security assessments of both infrastructure and model behaviour ensure defences keep pace with evolving threats. Compliance automation can further streamline regulatory adherence, verifying that models meet performance and data-handling standards while keeping development agile. This balance ensures MLOps pipelines remain both secure and efficient.
Integrating Machine Learning Workflows into Existing CI/CD Pipelines
Bringing machine learning (ML) workflows into your existing CI/CD setup doesn't mean starting from scratch. Most organisations can adapt their current infrastructure, adding ML-specific elements step by step while keeping things running smoothly. The trick is recognising how ML workflows differ from standard software deployment and addressing these differences thoughtfully. This approach allows for a seamless transition without disrupting ongoing operations.
The process requires careful planning. Teams need to think about how ML models will interact with existing systems, how data moves through the pipeline, and where to add new testing and validation steps. A measured approach that respects the complexity of ML, while upholding the reliability of production systems, is key to success.
Step-by-Step Integration Guide
Isolate ML environments with containers or virtual setups: This avoids conflicts between ML dependencies and existing applications. By keeping ML-specific libraries and frameworks separate, teams can experiment freely without affecting current deployments.
Set up independent data connections: ML models rely on consistent access to training and inference data, often requiring integration with databases, data lakes, or streaming platforms. Build and test these connections early in the process.
Incorporate model artefacts into version control: Treat ML models like code by integrating them into your existing Git workflows. This keeps everything organised and familiar for developers.
Add ML-specific tests to your pipeline: Beyond unit tests, include checks for data validation, model performance, and drift detection. Automate these tests to run whenever models are retrained or data changes significantly.
Roll out models gradually: Use canary or A/B testing methods to deploy models to a subset of users first. Monitor performance carefully before scaling up to full deployment.
Expand monitoring to track ML metrics: Extend your current monitoring tools to keep an eye on model accuracy, prediction latency, and data quality issues. This helps teams respond quickly to performance dips or changes in data patterns.
Overcoming Common Integration Challenges
Even with a clear plan, legacy systems and other challenges can complicate the integration process. Here’s how to tackle them:
Bridge legacy systems using API gateways or microservices: Instead of overhauling entire systems, use these approaches to connect ML components while keeping them independent.
Balance resources effectively: Set quotas to ensure ML workloads, especially those requiring GPUs or high-memory instances, don’t interfere with critical application deployments.
Leverage containerisation: When ML libraries have specific version requirements, create separate container images for ML tasks. This avoids conflicts and ensures reproducibility across environments.
Maintain visibility across processes: Use workflow engines that can manage both traditional and ML workflows, or establish clear handoff points between systems.
Extend existing security policies: ML pipelines often need access to sensitive data. Strengthen encryption, access controls, and audit trails without creating entirely new governance frameworks.
Develop robust testing strategies: Validate models against representative datasets and establish performance baselines. This accounts for real-world variations in data quality and distribution, which are critical for ML success.
Using Custom Automation and Consulting Expertise
Tackling these challenges often benefits from expert guidance. Complex MLOps integrations require a blend of technical know-how and tailored solutions to maintain stability while introducing new capabilities.
Custom automation tools can bridge the gap between existing CI/CD systems and ML-specific needs, enabling teams to enhance their workflows without discarding what already works.
Hokstad Consulting, for example, specialises in helping organisations integrate ML into CI/CD pipelines. They focus on building solutions that align with your current infrastructure, ensuring smooth adoption of MLOps practices without disrupting daily operations. Whether it’s extending Jenkins pipelines, integrating with cloud-native platforms, or crafting hybrid solutions, their tailored strategies address unique organisational challenges.
Another key focus is cost optimisation. By implementing auto-scaling, spot instance strategies, and resource scheduling, consulting services can prevent ML workloads from driving up infrastructure costs unnecessarily.
Finally, ongoing support ensures teams can adapt to new workflows and tackle unexpected hurdles. With access to DevOps expertise, organisations can resolve issues quickly, adopt best practices from the outset, and continually refine their MLOps pipelines as needs evolve.
Conclusion: Getting the Most from MLOps with CI/CD
Integrating MLOps with CI/CD reshapes how machine learning models are deployed, offering consistency, reliability, and speed while maintaining high production standards.
Transitioning from manual, one-off deployments to automated workflows marks a significant evolution in how businesses leverage artificial intelligence. Teams that embrace this integration can deploy models more frequently, with greater confidence, and with a reduced risk of production issues.
Key Benefits and Practical Approaches
By combining MLOps with CI/CD, organisations unlock a range of advantages and practical methodologies that streamline operations and improve outcomes.
- Enhanced Efficiency and Risk Reduction: Automated testing identifies potential performance issues before they reach end users, while version control ensures quick rollbacks when needed. These measures create a safer and more efficient deployment process.
- Experiment Tracking and Real-Time Monitoring: Tools for managing experiments, maintaining model registries, and monitoring live performance establish a strong backbone for enterprise-level machine learning operations.
- Containerisation: Running ML workloads alongside traditional applications preserves existing infrastructure investments and simplifies adoption through familiar deployment methods.
- Gradual Rollouts: Techniques like canary deployments and A/B testing allow teams to validate model performance on a smaller scale before rolling out fully, reducing costly errors and boosting confidence in automated workflows.
- Cost Management: Features such as auto-scaling, spot instance utilisation, and intelligent scheduling help control infrastructure costs, ensuring that the efficiencies gained from automation aren't outweighed by increased expenses.
When combined, these practices create a resilient and flexible framework for deploying machine learning models at scale, as detailed in earlier sections on pipeline design and integration.
Steps for Enterprises to Move Forward
To realise these benefits, businesses need a clear plan for implementation.
- Evaluate Current Capabilities: Start by assessing your existing pipelines to identify gaps and determine where MLOps and CI/CD can be integrated. Consider not only technical requirements but also the readiness of your team.
- Begin with Pilot Projects: Small-scale implementations are often the best way to test new practices. Pilot projects allow teams to experiment and learn without disrupting critical systems, paving the way for smoother, larger-scale rollouts.
- Seek Expert Support: For organisations with complex needs or tight deadlines, expert guidance can be invaluable. Hokstad Consulting is one such partner, offering tailored solutions that integrate seamlessly with existing infrastructure. Their approach ensures stability while enabling businesses to navigate technical challenges efficiently.
Investing in MLOps-integrated CI/CD pipelines leads to more reliable models, quicker deployment cycles, and lower operational overhead. As machine learning becomes a cornerstone of business strategy, mastering these practices will provide organisations with a lasting edge in an increasingly AI-driven world.
FAQs
How does MLOps enhance the deployment of machine learning models compared to traditional CI/CD pipelines?
MLOps transforms the way machine learning models are deployed by automating essential tasks like model training, testing, and deployment. This automation cuts down on manual work, reduces the chance of errors, and makes deployments quicker and more dependable. By integrating machine learning workflows into CI/CD pipelines, MLOps ensures that models can be updated and deployed smoothly alongside regular software updates.
While traditional CI/CD pipelines primarily cater to software development, MLOps goes further, offering a framework tailored for managing the entire machine learning lifecycle. This includes tasks like data versioning, retraining models, and monitoring their performance to ensure they stay accurate, scalable, and aligned with business goals. The payoff? Faster development cycles, better operational efficiency, and fewer risks during deployment.
What are the best practices for managing version control of data, models, and code in CI/CD pipelines with MLOps?
To manage version control effectively in CI/CD pipelines enhanced with MLOps, you need to focus on organised versioning systems for datasets, models, and code. This approach ensures everything is reproducible, traceable, and allows teams to collaborate seamlessly. Automating testing and validation processes is another key step, as it helps catch and address problems early in the development process.
Using tools tailored for machine learning workflows, like MLflow or DVC, can make tracking and managing data and models much easier. Additionally, keeping detailed documentation of changes and workflows not only aids compliance but also improves communication across teams. These practices help ensure smooth deployments and maintain the quality of machine learning solutions alongside regular software updates.
How can organisations balance cost optimisation and security when scaling MLOps pipelines?
Balancing cost efficiency with security when scaling MLOps pipelines demands a well-thought-out strategy. One effective method is adopting hybrid or multi-cloud setups. These allow organisations to optimise resource allocation while simultaneously adhering to stringent security requirements. The result? Reduced unnecessary spending without compromising on compliance.
Integrating automation into security processes is another smart move. For instance, continuous monitoring and embedding security checks directly into the MLOps pipeline can help address risks effectively without driving up expenses. On top of that, focusing on cost-conscious resource management and securing endpoints ensures that scaling efforts stay aligned with both budgetary constraints and security priorities.
By combining these approaches, organisations can expand their MLOps pipelines confidently, striking a solid balance between financial prudence and robust security measures.